Why fast but good publishing matters
If we are to enter the world of fast and good academic publishing, we need a dataset curation model that scales.

A large number of funders around the world now mandate publishing data needed to reproduce findings from the research they fund – at the same time as the paper is published. This is a change for academics. We have found through our State of Open Data reports that the majority of researchers are new to the concept of licensing content when they publish it. We also see lack of knowledge about how to describe datasets – particularly the title of the dataset. A rule of thumb is to describe a dataset in the same way that you would title a paper with a descriptive, meaningful title describing the research question, method, and/or finding.
The acceleration of public awareness around preprints and open data has occurred recently in line with the huge public interest in finding a treatment for COVID-19. This is nicely summed up by Digital Science CEO, Daniel Hook, in his recent whitepaper ‘How COVID-19 is Changing Research Culture’.
“The response has been immediate and intensive. Indeed, the research world has moved faster than many would have suspected possible. As a result, many issues in the scholarly communication system, that so many have been working to improve in recent years, are being highlighted in this extreme situation.”
Our recent work with the National Institutes of Health (NIH) on a pilot generalist repository for NIH-funded researchers highlighted some of the early issues that researchers face when publishing their data. This leads to a lot of poorly described and unintentionally obfuscated datasets. This can be very problematic.
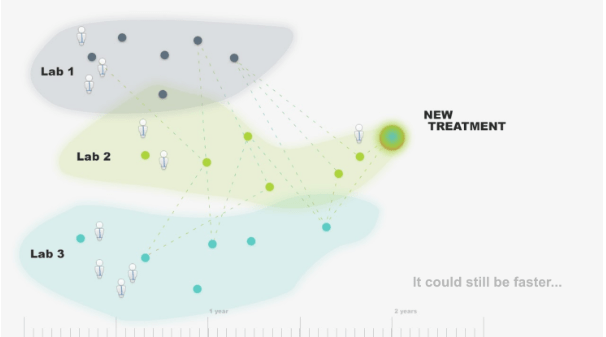
Consider the infographic above, where several labs are working to find a new treatment. By building on top of the work that has been done by one lab, another lab can advance at a faster rate. Add in multiple labs and this productivity is compounded. However, when reusing the ideas and data produced by another lab (represented as a dotted line above), it doesn’t take much for the process to fall apart. If the data is not open and FAIR, researchers will not be able to use it as a stepping stone in the hunt for a cure or treatment. This inevitably pushes back the time to find said treatment. If we’re using this analogy to represent a COVID-19 vaccine, pushing back the time potentially results in more deaths.
Unfortunately, a lot of researchers are still not making their data available in an open and FAIR manner. A quick search for the text string ‘data available upon request’ gives us over 4,000 papers. ‘Data available upon reasonable request’ gives us nearly 100 results, of which nearly one third were published in 2019. A recent study also highlighted where “Other statements suggested data were openly available, but failed to give enough information for readers to actually locate the data”
Number of papers published that include the phrase ‘data available upon request’ over time.
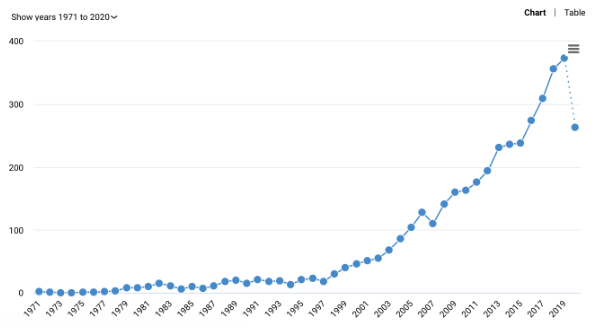
Fortunately, a global effort by funders such as the NIH to encourage data sharing and publishers to require data availability statements means that most researchers will soon be required to make their data publicly available as much as is feasible. Data available upon request will not suffice for most cases.
Making research available rapidly is important, but human checks on the content are too, as it needs to be not just openly available but also discoverable and reusable. Both preprints and data are amongst the new type of formats in which academic findings are disseminated. Whilst every preprint published on well known preprint platforms, such as ChemrXiv, TechrXiv and bioRxiv, have a basic human check – the majority of data published in generalist repositories does not.
For me, there are several tiers, which can be mapped back to the FAIR data principles. This list is not intended to be exhaustive, but indicative of the complexity and effort required at each stage.
Data with no checks that can be useful
- Academic files and metadata are available on the internet in repositories that follow best practice norms.
Top level check to make data Findable and Accessible
- The metadata is sufficient to be discoverable through a google search
- Policy compliant checks – the files have no PII, are under the correct license
- Appropriate use of PIDs and metadata standards
Interoperable and Reusable
- Files are in an open, preservation-optimised format
- Subject specific metadata schemas and file structures are applied in compliance with community best practice
- Forensic data checks for editing, augmenting
- Re-running of the results to ensure replicability
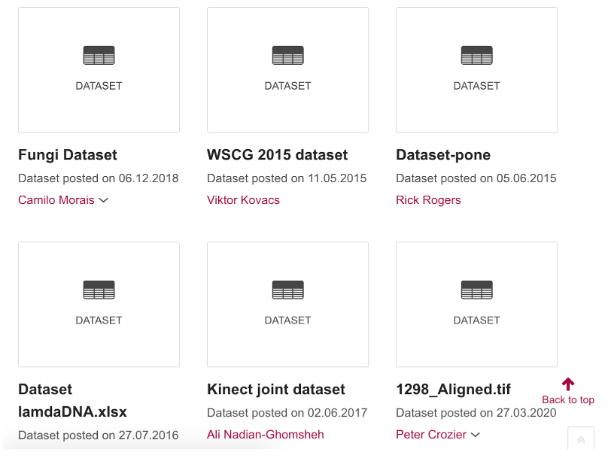
A search for the term dataset on the ‘free’ and non-curated figshare.com highlights a lack of descriptive titles in the screenshot below.
Our pilot with the NIH involved a data librarian on the Figshare team checking the metadata quality and working with the submitting researchers to make the datasets Findable and Accessible. The following checks and enhancements were carried out:
- Files match the description, can be opened, and are documented.
- Item type is appropriate for the NIH Figshare Instance.
- No obvious personally identifiable information is found in data or metadata and submitter has affirmed no PII is included.
- Metadata sufficiently describes the data or links to resources that further describe it.
- Embargoes are used appropriately.
- An appropriate license has been applied.
- NIH funding is specified and linked (if possible).
- Related publications are linked (when applicable).

As expected, these checks resulted in much more detailed metadata, when compared to datasets on figshare.com that were not checked or enhanced by a curation expert.
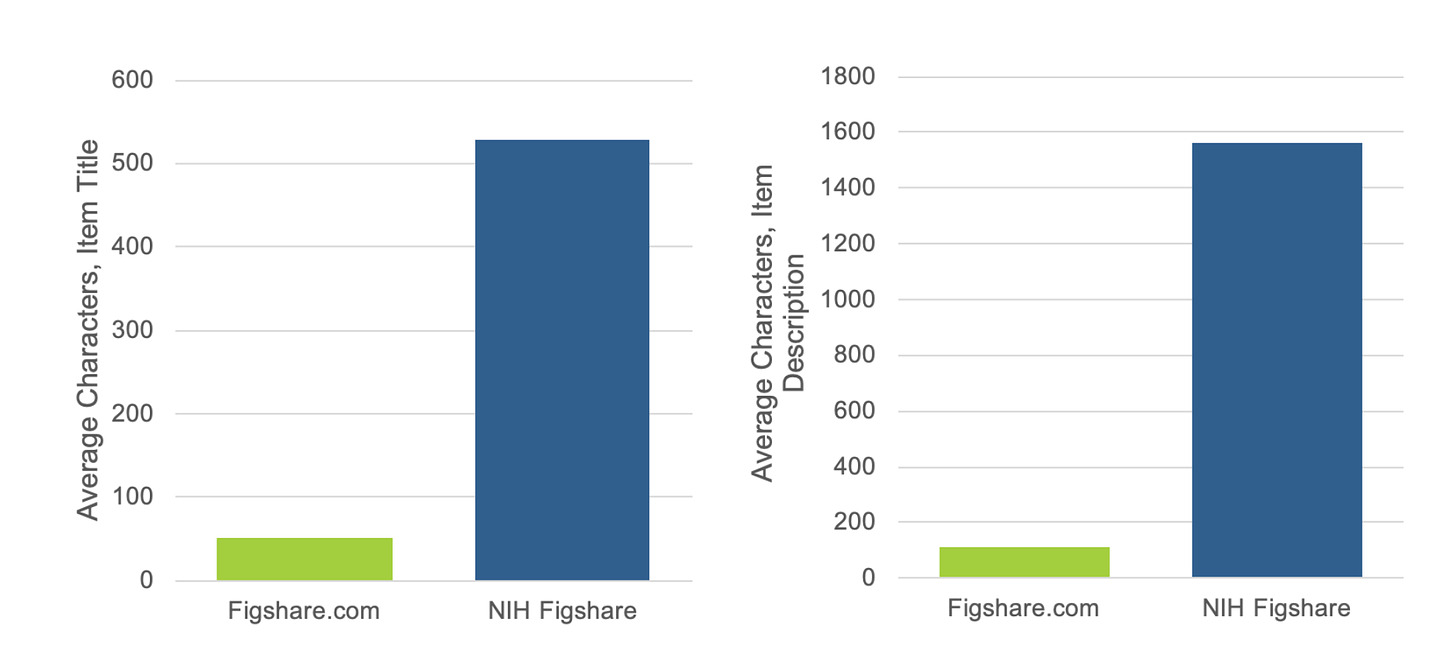
As raising awareness of new platforms is always tough (marketing is important) and takes time for adoption, we were aware that some NIH-funded researchers would continue to make use of the free figshare.com – even though they had the opportunity for free expert help with publishing on NIH Figshare. This actually proved to be beneficial in providing a comparison to consider the effect of metadata enhancement in datasets published in the NIH Figshare Instance.
We found preliminary evidence that datasets that had been checked by a data librarian got more downloads and many more views (2.5x) than those that hadn’t been checked. We also saw that the file size of the published datasets was much larger in the NIH Figshare Instance (8x greater) suggesting that there is a gap in the repositories space for datasets 100-500GB.
Taken together, these findings highlight the need for free-for-researcher generalist repositories, with human checks on the metadata to ensure FAIR-er, more impactful, and more reproducible research.
If we are to enter the world of fast and good academic publishing, we need a dataset curation model that scales.