Who benefits when, from FAIR data? Part 2 – Machines
AI and machine learning can be used to create more detailed, FAIR-er datasets to be consumed by the machines.

I think that Alphafold will win the Nobel Prize by 2030. In reality, I don’t think they will award it to the artificial intelligence (AI) itself, but to the lead authors on the Nature paper describing their work (John Jumper and Deepmind CEO, Demis Hassabis). AlphaFold is an AI program which performs predictions of protein structure. It is developed by DeepMind, a subsidiary of Alphabet (Google) that recently merged with the brain team from Google Research to become Google Deepmind. Whilst there are those who have suggested that the press coverage of Alphafold has been hyperbolic, for me it is less about whether ‘the protein folding problem has been solved’ and more about the giant leap that a field of research has progressed by due to one project.
Whilst Alphafold has got the lion’s share of the attention, there are several other advanced projects looking to have as much, if not more of an impact. All of these projects could not exist if it were not for large amounts of well described FAIR academic data.
NameFieldNotesDeepTrio (https://github.com/google/deepvariant)GenomicsA deep learning-based trio variant caller built on top of DeepVariant. DeepTrio extends DeepVariant’s functionality, allowing it to utilise the power of neural networks to predict genomic variants in trios or duosClimateNet (https://github.com/andregraubner/ClimateNet)Climate changeClimateNet seeks to address a major open challenge in bringing the power of deep learning to the climate community, viz. creating community-sourced, open-access, expert-labelled datasets and architectures for improved accuracy and performance on a range of supervised learning problems, where plentiful reliablylabelled training data is a requirementDeepChem (https://deepchem.io/about)Cheminformatics and drug discoveryDeepChem aims to provide a high quality, open-source toolchain that democratises the use of deep-learning in drug discovery, materials science, quantum chemistry, and biologyThe Materials Project (https://materialsproject.org/)Materials scienceThe Materials Project is an initiative that harnesses the power of AI and machine learning to accelerate materials discovery and design. It provides a vast and continuously growing database of materials properties, calculations, and experimental dataThe Dark Energy Survey (https://www.darkenergysurvey.org/)AstrophysicsThe Dark Energy Survey (DES) is a scientific project designed to study the nature of dark energy
Academic Projects making use of FAIR data and AI to drive systemic change in a research field.
Of course, when we refer to machines benefiting, what we are really referencing is human designed models benefitting from large swathes of well described data. The machines are made up of these algorithms, FAIR data and large amounts of compute. In a time when all of the low hanging fruit in research has been picked. Larger volumes of FAIR data can be processed by machines much more efficiently than humans. Processing this information to infer trends and predicted models allows human expertise to leverage information at a much faster rate, leading to new knowledge. We are in the ‘low hanging fruit’ phase of research powered by humans and machines (algorithms, FAIR data and compute).
A Virtuous Cycle
AI and machine learning can be used to create more detailed, FAIR-er datasets to be consumed by the machines. One of the more advanced areas this is happening in is mining the existing academic literature. Efforts like the AllenNLP Library and BioBERT, a biomedical language representation model designed for biomedical text mining tasks can help semantically enhance large datasets. Large language models (LLMs) and AI systems rely heavily on vast amounts of training data to learn patterns and generate accurate outputs. Open, FAIR academic data can serve as a valuable resource for training these models. By using diverse and well-curated academic data, LLMs and AI systems can better understand the nuances of various academic disciplines, terminology, and writing styles. This leads to improved performance in tasks such as natural language understanding, text generation, and information extraction.
Subject-specific data repositories provide homogenous FAIR data for a wide range of specialised domains. Incorporating open, FAIR academic data into LLMs enables them to develop domain-specific expertise. This expertise enhances their ability to understand and process domain-specific jargon, terminology, and concepts accurately. Consequently, these models can provide more insightful and nuanced responses in specialised areas.
Ultimately, as well as benefiting from having large amounts of well-described FAIR data, the machines can also support our original beneficiaries of FAIR data; the researchers.
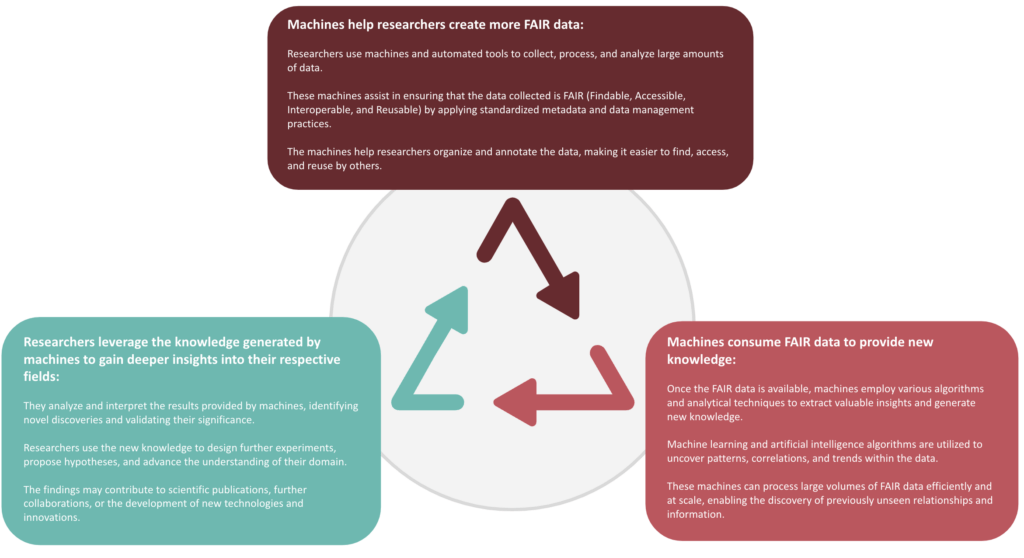
By leveraging large volumes of FAIR data, machines can accelerate the processing and analysis of information, leading to the generation of new knowledge and empowering researchers in their endeavours.
Academia needs to prioritise feeding the machines.