How is every country/funder/ institution doing at data sharing?
The 'Make Data Count Data Citation Corpus' looks for both DataCite DOIs and Accession numbers in the published literature. It basically tells you that "this publication DOI" mentions "this DataCite DOI or Accession number".
By taking this unstructured data and combining it with the Dimensions.ai corpus in Google big query, we can see what percentage of papers by different Countries, Funders, and Institutions link to a DataCite DOI or Accession number. You can test it out yourself below:
The data behind the app can be found here:
Hahnel, Mark (2024). Data behind State of Open Data 2024 Special Report: Bridging policy and practice in data sharing - Country, Funder and Affiliation Datasets. figshare. Dataset. https://doi.org/10.6084/m9.figshare.27900828.v1
I've included some screenshots of what kind of comparisons you can do:
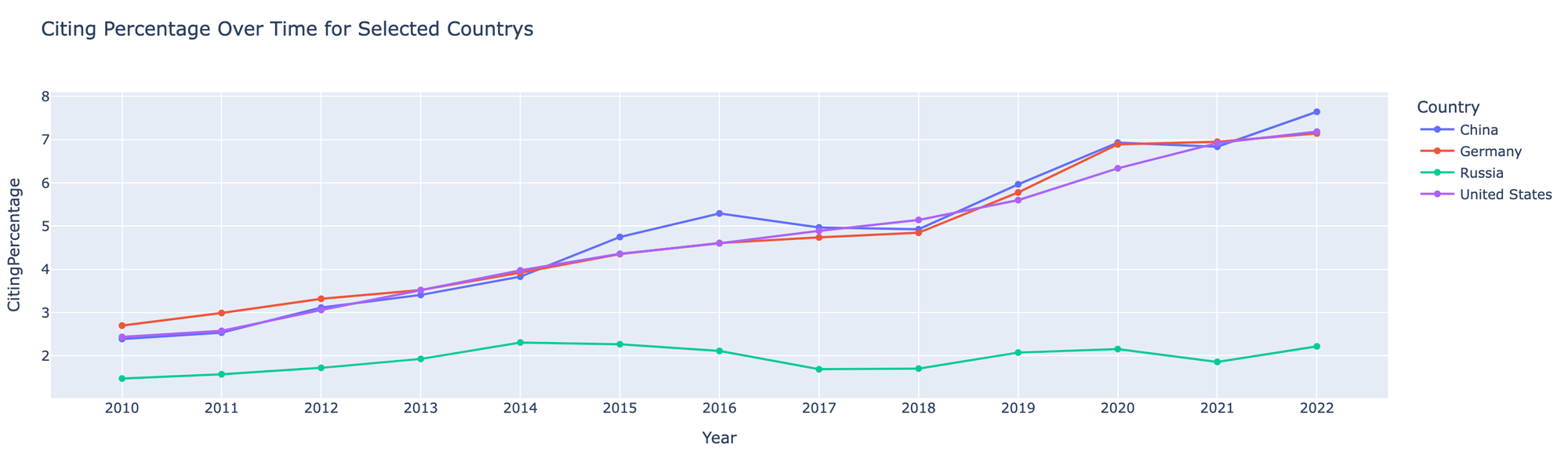
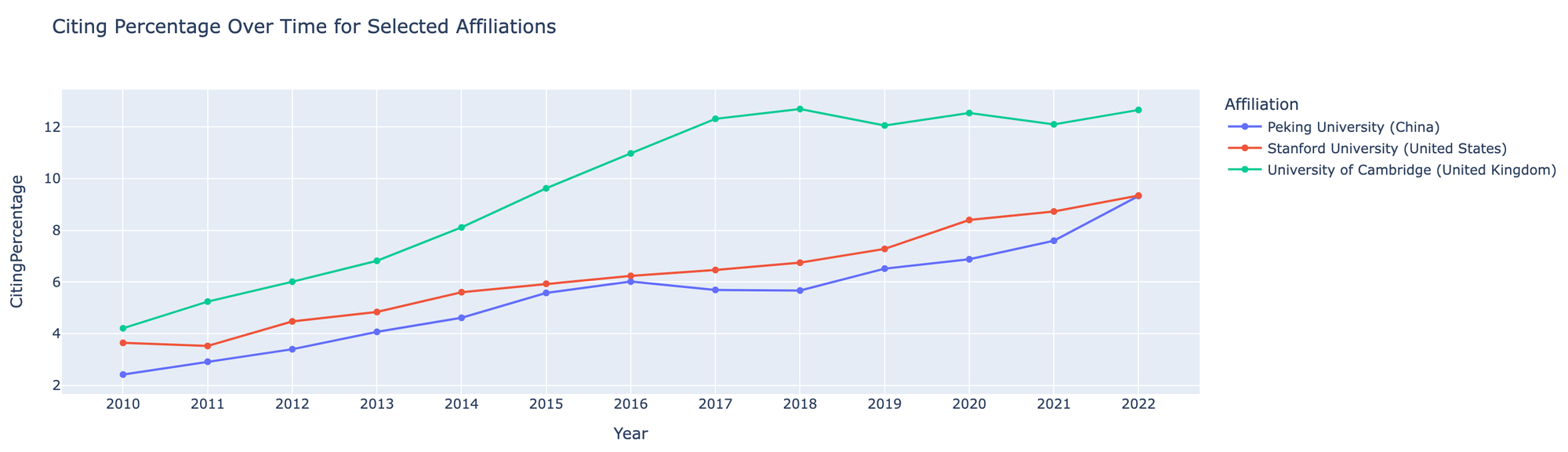
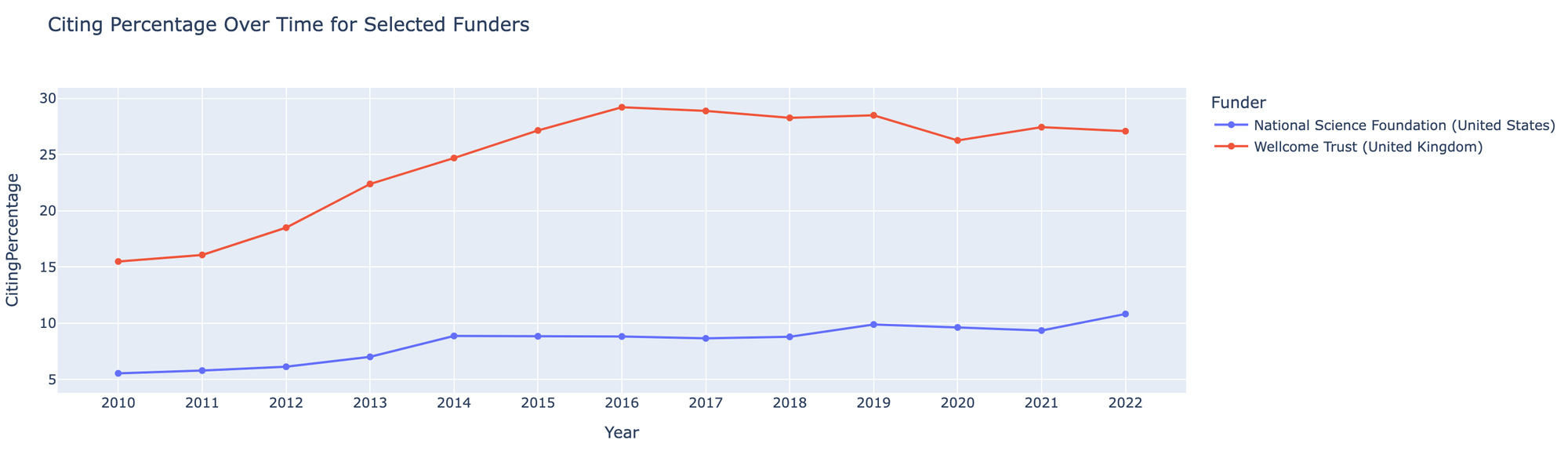
This shows the power of combining new datasets with well structured databases such as Dimensions in order to obtain new knowledge.